
Introduction
Have you ever stumbled upon a YouTube video where the content creator seemingly reads your mind with eerily accurate suggestions for what you should watch next? Or received an email from a company using language so natural and contextual that you’d swear a human wrote it? If so, you’ve likely witnessed the capabilities of transformers – a pioneering AI model that is quite literally transforming how we communicate with machines.
So what exactly are transformers, and why are they so powerful? Let’s take a step back and explore the history leading to this breakthrough.
The Progression to Transformers
Before transformers, the most widely used neural network architectures for processing sequential data like text or audio were:
Recurrent Neural Networks (RNNs): These models processed sequences in order, maintaining an internal “memory” state reflecting the inputs they had seen so far. However, RNNs struggled with long-range dependencies in data.
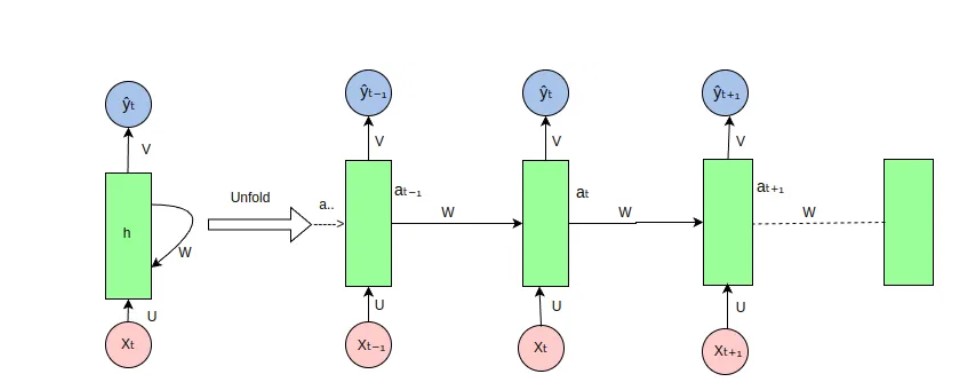
Long Short-Term Memory (LSTMs): LSTMs are a special RNN architecture designed to better handle long sequences by selectively remembering and forgetting information over time. They achieved strong results for many language tasks.
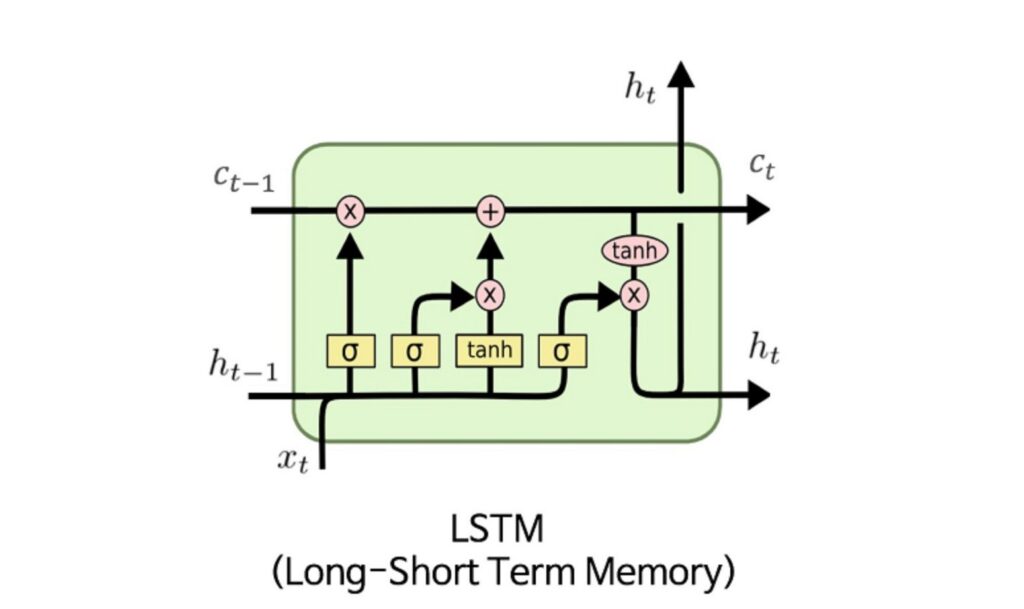
While LSTMs were a major advancement, they were still inherently limited by their sequential nature. They could only process sequences in a strict order, making it difficult to fully parallel inputs and learn broader contextual relationships.
What are Transformers?
This is where transformers made their revolutionary entrance…
Transformers are a type of neural network architecture designed to handle sequential data like text, audio, or video in a novel way. Unlike traditional models that process data sequentially (word-by-word or frame-by-frame), transformers can analyze entire sequences in parallel while considering contextual relationships between each component.
This “global” self-attention mechanism allows transformers to weigh the importance and relevance of different word/data relationships across an entire sequence. It’s analogous to how humans naturally interpret language – integrating the full context surrounding words instead of rigidly processing them one-by-one.
Transformers in Action: Practical Applications
The parallels with human cognition have unlocked transformative use cases across industries:
Natural Language Processing
- Highly fluent text generation (e.g. article/story writing, code generation)
- Accurate text summarization
- Robust question-answering and conversation abilities
Machine Translation
- State-of-the-art translation quality between languages
- Better handling of context, idioms, and nuance
Text Analysis
- Precise sentiment analysis of opinions/emotions
- Intelligent extraction of insights from large document troves
Recommendations
- Spotify song suggestions based on listening patterns/preferences
- YouTube’s uncannily accurate “watch next” video feeds
The diverse applications stem from transformers’ flexible architecture that can be trained on vast datasets to master AI tasks imitating human cognition.
Landmark Transformer Models
A few transformer models that have made massive waves:
BERT: Developed by Google, the Bidirectional Encoder Representations from Transformers (BERT) revolutionized question answering and text analysis by training on huge language corpora. It infers context from the text in both directions simultaneously.
GPT-3: The massive Generative Pre-trained Transformer 3 from OpenAI showed transformers’ incredible capacity to generate humanlike content after training on nearly a trillion words from the internet.
AlphaFold: This breakthrough transformer protein structure prediction system developed by DeepMind solved a 50-year grand challenge in biology.
The Future of Transformers
With the floodgates opened, transformers have sparked a modern AI renaissance. Research is rapidly evolving to make models more capable, efficient, and secure for real-world applications.
While early transformers grappled with limitations like maxsequencelengths and immense computational costs to train, innovations like Sparse Transformers, Longformers, and Efficient Transformers have enabled analyzing lengthier inputs. Hardware optimizations like NVIDIA’s Transformer Engine are accelerating training times.
On the ethics front, work remains to make transformers more transparent, robust to attacks, and aligned with human values as their influence grows. But their generalizability and ability to learn from data rather than rigid programming has catalyzed amazing possibilities.
Transformers have already transformed AI from arcane science to real-world utility. But this is merely the beginning of their transformative potential to reshape how machines fundamentally interface with the world around us. The future of transformers and their capabilities to emulate human intelligence remains utterly fascinating.
10 Important Questions and Answers on Transformers
- Can you explain how attention mechanisms work in transformer models, and why are they important?
- Answer: Attention mechanisms in transformer models allow the model to focus on different parts of the input sequence when making predictions. They compute attention scores for each input element and use them to calculate weighted sums, capturing dependencies between words more effectively. This enables the model to handle long-range dependencies and improve performance on various NLP tasks.
- Describe a project where you implemented a transformer-based model. What challenges did you encounter, and how did you address them?
- Answer: In a sentiment analysis project, I implemented a BERT-based model to classify movie reviews. One challenge was fine-tuning the model on a relatively small dataset. To address this, I used techniques like data augmentation, regularization, and progressive resizing of input sequences to prevent overfitting and improve generalization performance.
- How do you handle overfitting when training transformer models on limited data?
- Answer: To mitigate overfitting, I employ techniques such as dropout regularization, early stopping, and data augmentation. Additionally, I leverage transfer learning by fine-tuning pre-trained transformer models on similar tasks or domains, which helps the model generalize better to new data.
- What strategies do you use to optimize the performance of a transformer model in terms of speed and memory usage?
- Answer: I utilize techniques like gradient checkpointing, model pruning, and quantization to reduce memory footprint and improve inference speed without sacrificing performance. I also leverage hardware accelerators like GPUs or TPUs for parallel processing to expedite training and inference.
- Have you worked with any domain-specific variations of transformer models, such as medical or financial text data? If so, what were the unique challenges you faced?
- Answer: Yes, I’ve worked on a medical NLP project where I fine-tuned a transformer model for clinical text classification. One challenge was handling noisy and unstructured medical text data, which required careful preprocessing and domain-specific tokenization strategies to ensure meaningful representations.
- How do you evaluate the performance of a transformer model on a specific NLP task? Can you discuss any metrics or techniques you find particularly useful?
- Answer: I typically use standard evaluation metrics such as accuracy, precision, recall, F1 score, and area under the ROC curve (AUC-ROC) for classification tasks. For sequence generation tasks, I evaluate using metrics like BLEU score, ROUGE score, and perplexity. I also perform error analysis to gain insights into model behavior and identify areas for improvement.
- What are some considerations to keep in mind when fine-tuning a pre-trained transformer model for a new task or domain?
- Answer: When fine-tuning a pre-trained transformer model, it’s crucial to select an appropriate learning rate, batch size, and number of training epochs. Additionally, attention should be paid to the choice of task-specific objective function and the amount of training data available. Regularization techniques and hyperparameter tuning can further enhance performance.
- Have you experimented with incorporating additional features or modalities into a transformer model, such as image features or tabular data? If so, what were the results?
- Answer: Yes, I’ve explored multi-modal transformer architectures that combine text with image or tabular data for tasks like visual question answering and recommendation systems. By concatenating or fusing different modalities at various layers of the transformer, I achieved improved performance compared to single-modal approaches.
- Can you discuss any experiences you’ve had with deploying transformer models in production environments? What were the key challenges, and how did you overcome them?
- Answer: In a sentiment analysis project for a social media platform, deploying the transformer model required optimizing inference speed and memory usage to handle real-time user interactions. We implemented model serving using containerization and load balancing techniques to scale the application horizontally. Continuous monitoring and performance tuning ensured smooth operation in production.
- In your opinion, what are the most promising research directions or advancements in the field of transformer models, and how do you see them impacting real-world applications in the near future?
- Answer: I believe advancements in areas like few-shot learning, model compression, and cross-modal understanding hold great promise for transformer models. Techniques such as meta-learning, knowledge distillation, and joint training of text and other modalities will enable transformers to learn more efficiently from limited data and generalize better across diverse tasks and domains, leading to breakthroughs in real-world applications such as personalized recommendation systems, medical diagnosis, and autonomous systems.
A Noteworthy Ending
It’s worth noting that while transformers have made unprecedented strides, they are not a perfect or complete solution. Limitations like bias, hallucinations, and inability to learn continually plague current architectures. Bleeding-edge research into areas like Constituitional AI, Differentiable Neural Rendering, and Neural Ordinary Differential Equations may eventually supersede or complement transformers.
Additionally, the rise of specialized hardware like GPUs, TPUs, and AI-focused chips has been instrumental to transformers’ success by enabling the high computational demands of self-attention. Continued hardware and software co-design will likely accelerate progress.
Ultimately, transformers have cracked the code of abstracting away the complexities of sequential data to reveal powerful patterns. As technology rapidly evolves alongside our ability to responsibly wield it, the future of human-machine interactions appears to be converging towards seamless cooperation and symbiosis. Transformers are a pivotal catalyst propelling us towards that future.
